




In the past, kings and leaders used oracles and magicians to help them predict the future — or at least get some good advice due to their supposed power to perceive hidden information. Nowadays, we live in a society obsessed with quantifying everything. So we have data scientists to do this job.
Data scientists use statistical models, numerical techniques and advanced algorithms that didn’t come from statistical disciplines, along with the data that exist on databases, to find, to infer, to predict data that doesn’t exist yet. Sometimes this data is about the future. That is why we do a lot of predictive analytics and prescriptive analytics.
Here are some questions to which data scientists help find answers:
- Who are the students with high propensity to abandon the class? For each one, what are the reasons for leaving?
- Which house has a price above or below the fair price? What is the fair price for a certain house?
- What are the hidden groups that my clients classify themselves?
- Which future problems this premature child will develop?
- How many calls will I get in my call center tomorrow 11:43 AM?
- My bank should or should not lend money to this customer?
Note how the answer to all these question is not sitting in any database waiting to be queried. These are all data that still doesn’t exist and has to be calculated. That is part of the job we data scientists do.
Throughout this article you’ll learn how to prepare a Fedora system as a Data Scientist’s development environment and also a production system. Most of the basic software is RPM-packaged, but the most advanced parts can only be installed, nowadays, with Python’s pip tool.
Jupyter — the IDE
Most modern data scientists use Python. And an important part of their work is EDA (exploratory data analysis). EDA is a manual and interactive process that retrieves data, explores its features, searches for correlations, and uses plotted graphics to visualize and understand how data is shaped and prototypes predictive models.
Jupyter is a web application perfect for this task. Jupyter works with Notebooks, documents that mix rich text including beautifully rendered math formulas (thanks to mathjax), blocks of code and code output, including graphics.
Notebook files have extension .ipynb, which means Interactive Python Notebook.
Setting up and running Jupyter
First, install essential packages for Jupyter (using sudo):
$ sudo dnf install python3-notebook mathjax sscg
You might want to install additional and optional Python modules commonly used by data scientists:
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
Set a password to log into Notebook web interface and avoid those long tokens. Run the following command anywhere on your terminal:
$ mkdir -p $HOME/.jupyter
$ jupyter notebook password
Now, type a password for yourself. This will create the file $HOME/.jupyter/jupyter_notebook_config.json with your encrypted password.
Next, prepare for SSLby generating a self-signed HTTPS certificate for Jupyter’s web server:
$ cd $HOME/.jupyter; sscg
Finish configuring Jupyter by editing your $HOME/.jupyter/jupyter_notebook_config.json file. Make it look like this:
{
"NotebookApp": {
"password": "sha1:abf58...87b",
"ip": "*",
"allow_origin": "*",
"allow_remote_access": true,
"open_browser": false,
"websocket_compression_options": {},
"certfile": "/home/aviram/.jupyter/service.pem",
"keyfile": "/home/aviram/.jupyter/service-key.pem",
"notebook_dir": "/home/aviram/Notebooks"
}
}
The parts in red must be changed to match your folders. Parts in blue were already there after you created your password. Parts in green are the crypto-related files generated by sscg.
Create a folder for your notebook files, as configured in the notebook_dir setting above:
$ mkdir $HOME/Notebooks
Now you are all set. Just run Jupyter Notebook from anywhere on your system by typing:
$ jupyter notebook
Or add this line to your $HOME/.bashrc file to create a shortcut command called jn:
alias jn='jupyter notebook'
After running the command jn, access https://your-fedora-host.com:8888 from any browser on the network to see the Jupyter user interface. You’ll need to use the password you set up earlier. Start typing some Python code and markup text. This is how it looks:
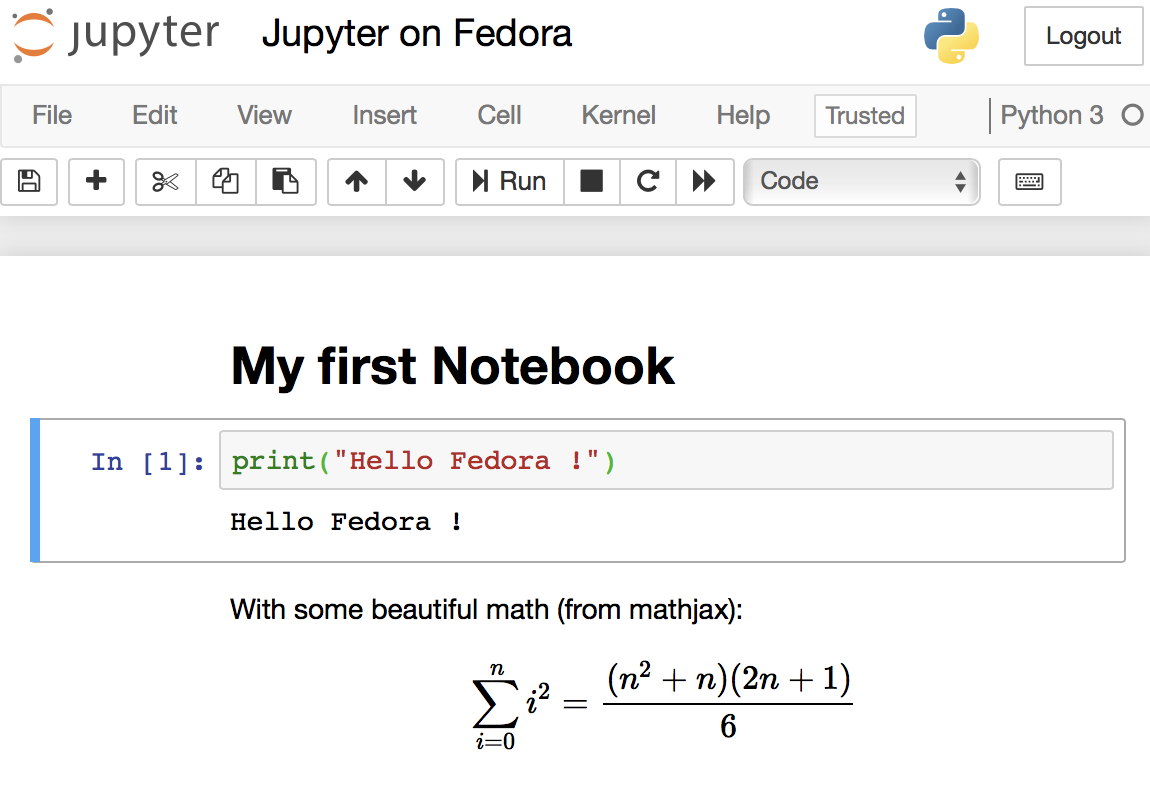
In addition to the IPython environment, you’ll also get a web-based Unix terminal provided by terminado. Some people might find this useful, while others find this insecure. You can disable this feature in the config file.
JupyterLab — the next generation of Jupyter
JupyterLab is the next generation of Jupyter, with a better interface and more control over your workspace. It’s currently not RPM-packaged for Fedora at the time of writing, but you can use pip to get it installed easily:
$ pip3 install jupyterlab --user
$ jupyter serverextension enable --py jupyterlab
Then run your regular jupiter notebook command or jn alias. JupyterLab will be accessible from http://your-linux-host.com:8888/lab.
Tools used by data scientists
In this section you can get to know some of these tools, and how to install them. Unless noted otherwise, the module is already packaged for Fedora and was installed as prerequisites for previous components.
Numpy
Numpy is an advanced and C-optimized math library designed to work with large in-memory datasets. It provides advanced multidimensional matrix support and operations, including math functions as log(), exp(), trigonometry etc.
Pandas
In this author’s opinion, Python is THE platform for data science mostly because of Pandas. Built on top of numpy, Pandas makes easy the work of preparing and displaying data. You can think of it as a no-UI spreadsheet, but ready to work with much larger datasets. Pandas helps with data retrieval from a SQL database, CSV or other types of files, columns and rows manipulation, data filtering and, to some extent, data visualization with matplotlib.
Matplotlib
Matplotlib is a library to plot 2D and 3D data. It has great support for notations in graphics, labels and overlays
Seaborn
Built on top of matplotlib, Seaborn’s graphics are optimized for a more statistical comprehension of data. It automatically displays regression lines or Gauss curve approximations of plotted data.
StatsModels
StatsModels provides algorithms for statistical and econometrics data analysis such as linear and logistic regressions. Statsmodel is also home for the classical family of time series algorithms known as ARIMA.
Scikit-learn
The central piece of the machine-learning ecosystem, scikit provides predictor algorithms for regression (Elasticnet, Gradient Boosting, Random Forest etc) and classification and clustering (K-means, DBSCAN etc). It features a very well designed API. Scikit also has classes for advanced data manipulation, dataset split into train and test parts, dimensionality reduction and data pipeline preparation.
XGBoost
XGBoost is the most advanced regressor and classifier used nowadays. It’s not part of scikit-learn, but it adheres to scikit’s API. XGBoost is not packaged for Fedora and should be installed with pip. XGBoost can be accelerated with your nVidia GPU, but not through its pip package. You can get this if you compile it yourself against CUDA. Get it with:
$ pip3 install xgboost --user
Imbalanced Learn
imbalanced-learn provides ways for under-sampling and over-sampling data. It is useful in fraud detection scenarios where known fraud data is very small when compared to non-fraud data. In these cases data augmentation is needed for the known fraud data, to make it more relevant to train predictors. Install it with pip:
$ pip3 install imblearn --user
NLTK
The Natural Language toolkit, or NLTK, helps you work with human language data for the purpose of building chatbots (just to cite an example).
SHAP
Machine learning algorithms are very good on predicting, but aren’t good at explaining why they made a prediction. SHAP solves that, by analyzing trained models.
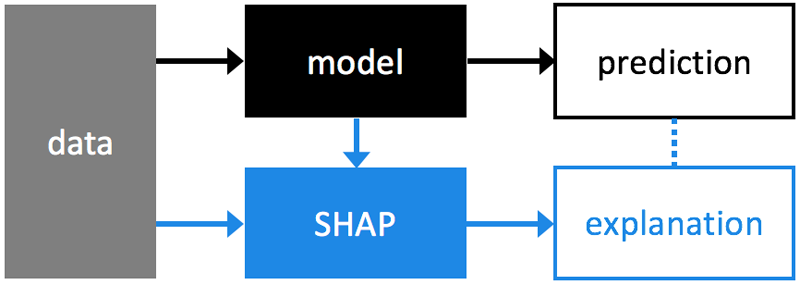
Install it with pip:
$ pip3 install shap --user
Keras
Keras is a library for deep learning and neural networks. Install it with pip:
$ sudo dnf install python3-h5py
$ pip3 install keras --user
TensorFlow
TensorFlow is a popular neural networks builder. Install it with pip:
$ pip3 install tensorflow --user
Photo courtesy of FolsomNatural on Flickr (CC BY-SA 2.0).

Raul Giucich
Hi Avil, thanks for your article. I’m starting in data science and this kind of reference is very useful.
I found a typo in keras section, in dnf sentence, the command must be “install” an l is missing.
Thanks again.
Best regards
Paul W. Frields
@Raul: Thanks, this is fixed.
Ankur Sinha "FranciscoD"
I think we should probably be suggesting people use virtual environments when installing stuff using pip, but that’s another blog post (or quick-doc)?
https://docs.python.org/3/library/venv.html
Jason
Alternatively, conda can manage a lot of the data sciency stuff, including environments.
https://www.anaconda.com/distribution/
M. "Loffi"
I’d love to see a post about that.
Avi Alkalay
Virtual environments are useful in development scenarios where multiple projects happening in a certain machine have conflicting requirements, like different versions of same Python module.
Virtual environments (in the Python sense) is very unnatural in production environments.
It is a better practice to reach same objectives using methods that are closer to production environments, as multiple Docker images, one for each project or requirement set. This technique comes from the DevOps world and it’s called Shift Left, because it anticipates (shift left) to the developer’s environment a step of the delivery pipeline that would need to happen anyway.
Docker, containers and shift left are the way to go in my opinion, while virtualenv is a Python-specific hack.
Avi Alkalay
Here are some packages and modules that I forgot to add in the original article:
LEAFLET
Interactive mapping framework that uses Google Maps and other backends to render its maps. Install it with:
pip3 install leaflet –user
CARTOPY
Plot data on top of high resolution open source maps. Cartopy provides raster and vector maps of the world (but no street maps as Google Maps). Install it with:
sudo dnf install python3-cartopy.x86_64
PLOTLY
Visualisation framework which is more advanced that Matplotlib. Plotly supports animations and user interactivity. Plotly is part of a family of tools which also includes Dash, a Python BI framework. Install it with:
dnf install python3-retrying.noarch
pip3 install plotly –user
Mehdi
Love the article. Gives good insight to machine learning packages in 10 minutes. Thanks Avi.
Kiril
Why not use conda for python package management?
drakkai
People interested in the Jupyter may also be interested in https://colab.research.google.com/
Avi Alkalay
One more addition related to web scraping, or the technique of extracting structured data from web pages.
BEAUTIFULSOUP
The most common library for HTML parsing and data extraction. Install it with:
$ sudo dnf install python3-beautifulsoup4
LXML
Similar to BeautifulSoup but goes lower in the XML. Get it:
$ dnf install python3-lxml
SCRAPY
A more advanced framework which supports multiple languages and the shell command line. Get it with:
$ sudo dnf install python3-scrapy
SELENIUM
If you are scrapping more dynamic and AJAX-constructed web content, Scrapy, and BeautifulSoup won’t work. Enter Selenium which uses your installed browser (Chromium, Firefox and their headless versions) to load the page and run its JavaScript code before scrapping (with Scrapy and BeautifulSoup). Get it:
$ sudo dnf install python3-selenium
Here is an advanced article that discusses advanced scraping techniques: https://www.codementor.io/blog/python-web-scraping-63l2v9sf2q
Musashi
This is a great article!
I personally work a lot on natural language processing, and recently I’ve been working with a wonderful library called spaCy.
Also, for what it’s worth, I’m a fan of using anaconda as a package/environment manager.
Avi Alkalay
For those looking into Conda/Anaconda, I want to recall that Conda is a Python distribution, by the way a not very stable one. And I think there is no good reason to use a Python distribution (Conda) on top of the best Python distribution (Fedora) which is fully integrated with the underlying OS (also Fedora).
Besides, I had a bad time with Conda packages. They were unstable and outdated when I had to use it, for exemple TensorFlow.
If something you need is not RPM-packaged from Fedora, use pip3 to get it. It’s the most natural way to work with Python.
Andreas T
My experience with Anaconda is quite the opposite to the Avi’s comment. Using conda-forge, packages are up to date (e.g. tensorflow) and stable. This is based on use in an academic research lab.
Collaborating in a team with users that run different unix versions and windows, running Anaconda provides the same base for all and makes code sharing easy.
Michael
I switched to Fedora (from Ubuntu) just before SciPy2019. Everything here used Jupyter notebooks as the standard way of sharing and teachine data science.
Fedora has been brilliant.
I think I would still suggest people use Anaconda to work with Jupyter on Fedora, rather than trying ot have it run natively on Fedora. But that is not remotely a criticism of Fedora – it’s just that the very large majority of the people who use Jupyter use Anaconda to manage scientific python environments (including use of Jupyter).
Michael
Elliott S
There’s no need to install
explicitly; it’s a dependency of
already.
Also, s/Numpy/NumPy/g.
Matthew Fallon
Just wanted to drop in one more important extension that people may need or want for map visualization, the mapview and other widgets extension that allows for map visualization.
WIDGETS NB EXTENSION:
run:
$pip install widgetsnbextension
With whatever command arguments or versions you need for pip
or install using the jupyter notebook commands for extensions:
$jupyter nbextension install –py widgetsnbextension
$jupyter nbextension enable –py widgetsnbextension
with the –user flag or another flag for each just like with pip.
This will give you access to widgets such as MapView which will interface with other data visualization software, one of which I was recently turned on to was arcgis which allows for maps with complex data visuals overlaid on it and uses MapView for all of it.
ARCGIS:
Install with:
$pip install arcgis
or again with:
$jupyter nbextension install –py arcgis
$jupyter nbextension enable –py arcgis
With corresponding flags again, this second mode allows for modules to be controlled and turned on and off through jupyter.
Just wanted to offer these because they will not be installed out of the box with the way presented here, this is sort of the very manual non-automated way of installing it and you will need to put each of these pieces on your install as one is dependent on the other. Or, as mentioned in other comments, it may be preffered to install through something like conda to make sure everything is installed by default.
r44e54
How changing language to Polish?
I’m talking about frontend language not for language similar Ruby or Perl