



Backing up data is one of the most important tasks everyone should be doing regularly. This series will demonstrate using three software tools to backup your important data.
When planning a backup strategy, consider the “Three Rs of backup”:
- Redundant: Backups must be redundant. Backup media can fail. The backup storage site can be compromised (fire, theft, flood, etc.). It’s always a good idea to have more than one destination for backup data.
- Regular: Backups only help if you run them often. Schedule and run them regularly to keep adding new data and prune off old data.
- Remote: At least one backup should be kept off-site. In the case of one site being physically compromised (fire, theft, flood, etc.), the remote backup becomes a fail-safe.
duplicity is an advanced commandline backup utility built on top of librsync and GnuPG. By producing GPG-encrypted backup volumes in tar-format, it offers secure incremental archives (a huge space saver, especially when backing up to remote services like S3 or an FTP server).
To get started, install duplicity:
dnf install duplicity
Choose a backend
duplicity supports a lot of backend services categorized into two groups: hosted storage providers and local media. Selecting a backend is mostly a personal preference, but select at least two (Redundant). This article uses an Amazon S3 bucket as an example backend service.
Set up GnuPG
duplicity encrypts volumes before uploading them to the specified backend using a GnuPG key. If you haven’t already created a GPG key, follow GPG key management, part 1 to create one. Look up the long key ID and keep it nearby:
gpg2 --list-keys --keyid-format long me@mydomain.com
Set up Amazon AWS
AWS recommends using individual accounts to isolate programmatic access to your account. Log into the AWS IAM Console. If you don’t have an AWS account, you’ll be prompted to create one.
Click on Users in the list of sections on the left. Click the blue Add user button. Choose a descriptive user name, and set the Access type to Programmatic access only. There is no need for a backup account to have console access.
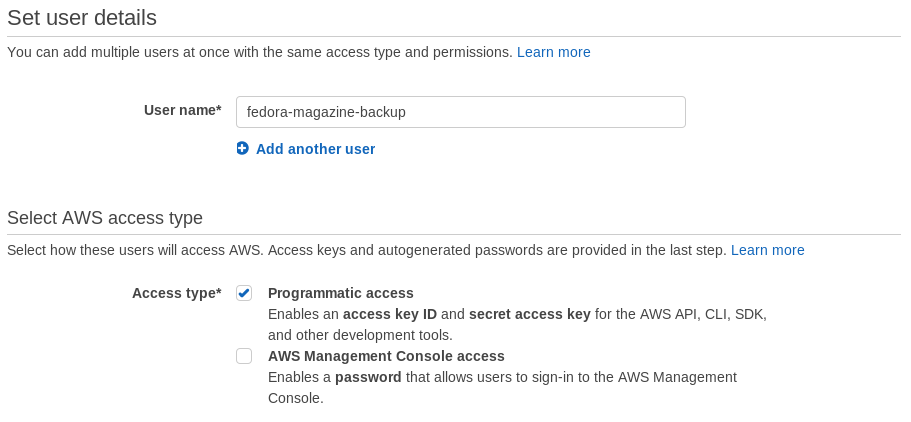
Next, attach the AmazonS3FullAccess policy directly to the account. duplicity needs this policy to create the bucket automatically the first time it runs.

After the user is created, save the access key ID and secret access key. They are required by duplicity when connecting to S3.
Choose backup data
When choosing data to back up, a good rule of thumb is to back up data you’ve created that can’t be re-downloaded from the Internet. Good candidates that meet this criteria are ~/Documents and ~/Pictures. Source code and “dot files” are also excellent candidates if they aren’t under version control.
Create a full backup
The general form for running duplicity is:
duplicity [OPTIONS] SRC DEST
In order to backup ~/Documents, but preserve the Documents folder within the backup volume, run duplicity with $HOME as the source, specify the –include option to include only ~/Documents, and exclude everything else with –exclude ‘**’. The –include and –exclude options can be combined in various ways to create specific file matching patterns. Experiment with these options before creating the initial backup. The –dry-run option simulates running duplicity. This is a great way to preview what a particular duplicity invocation will do.
duplicity will automatically determine whether a full or incremental backup is needed. The first time you run a source/destination, duplicity creates a full backup. Be sure to first export the access key ID and secret access key as environment variables. The –name option enables forward compatibility with duply (coming in part 2). Specify the long form GPG key ID that should be used to sign and encrypt the backup volumes with –encrypt-sign-key.
$ export AWS_ACCESS_KEY_ID=******************** $ export AWS_SECRET_ACCESS_KEY=**************************************** $ duplicity --dry-run --name duply_documents --encrypt-sign-key **************** --include $HOME/Documents --exclude '**' $HOME s3+http://**********-backup-docs Local and Remote metadata are synchronized, no sync needed. Last full backup date: none GnuPG passphrase: GnuPG passphrase for signing key: No signatures found, switching to full backup. --------------[ Backup Statistics ]-------------- StartTime 1499399355.05 (Thu Jul 6 20:49:15 2017) EndTime 1499399355.09 (Thu Jul 6 20:49:15 2017) ElapsedTime 0.05 (0.05 seconds) SourceFiles 102 SourceFileSize 40845801 (39.0 MB) NewFiles 59 NewFileSize 40845801 (39.0 MB) DeletedFiles 0 ChangedFiles 0 ChangedFileSize 0 (0 bytes) ChangedDeltaSize 0 (0 bytes) DeltaEntries 59 RawDeltaSize 0 (0 bytes) TotalDestinationSizeChange 0 (0 bytes) Errors 0 -------------------------------------------------
When you’re ready, remove the –dry-run option and start the backup. Plan ahead for the initial backup. It can often be a large amount of data and can take hours to upload, depending on your Internet connection.
After the backup is complete, the AWS S3 Console lists the new full backup volume.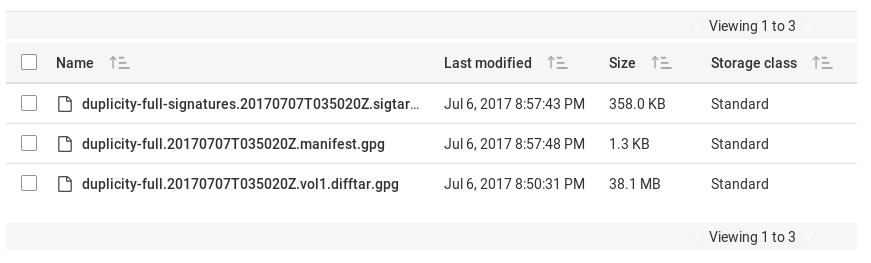
Create an incremental backup
Run the same command again to create an incremental backup.
$ export AWS_ACCESS_KEY_ID=******************** $ export AWS_SECRET_ACCESS_KEY=**************************************** $ duplicity --dry-run --name duply_documents --encrypt-sign-key **************** --include $HOME/Documents --exclude '**' $HOME s3+http://**********-backup-docs Local and Remote metadata are synchronized, no sync needed. Last full backup date: Thu Jul 6 20:50:20 2017 GnuPG passphrase: GnuPG passphrase for signing key: --------------[ Backup Statistics ]-------------- StartTime 1499399964.77 (Thu Jul 6 20:59:24 2017) EndTime 1499399964.79 (Thu Jul 6 20:59:24 2017) ElapsedTime 0.02 (0.02 seconds) SourceFiles 60 SourceFileSize 40845801 (39.0 MB) NewFiles 3 NewFileSize 8192 (8.00 KB) DeletedFiles 0 ChangedFiles 0 ChangedFileSize 0 (0 bytes) ChangedDeltaSize 0 (0 bytes) DeltaEntries 3 RawDeltaSize 0 (0 bytes) TotalDestinationSizeChange 845 (845 bytes) Errors 0 -------------------------------------------------
Again, the AWS S3 Console lists the new incremental backup volumes.

Restore a file
Backups aren’t useful without the ability to restore from them. duplicity makes restoration straightforward by simply reversing the SRC and DEST in the general form: duplicity [OPTIONS] DEST SRC.
$ export AWS_ACCESS_KEY_ID=******************** $ export AWS_SECRET_ACCESS_KEY=**************************************** $ duplicity --name duply_documents s3+http://**********-backup-docs $HOME/Restore Local and Remote metadata are synchronized, no sync needed. Last full backup date: Thu Jul 6 21:46:01 2017 GnuPG passphrase: $ du -sh Restore/ 783M Restore/
This restores the entire backup volume. Specific files or directories are restored using the –file-to-restore option, specifying a path relative to the backup root. For example:
$ export AWS_ACCESS_KEY_ID=******************** $ export AWS_SECRET_ACCESS_KEY=**************************************** $ duplicity --name duply_documents --file-to-restore Documents/post_install s3+http://**********-backup-docs $HOME/Restore Local and Remote metadata are synchronized, no sync needed. Last full backup date: Tue Jul 4 14:16:00 2017 GnuPG passphrase: $ tree Restore/ Restore/ ├── files │ ├── 10-doxie-scanner.rules │ ├── 99-superdrive.rules │ └── simple-scan.dconf └── post_install.sh 1 directory, 4 files
Automate with a timer
The example above is clearly a manual process. “Regular” from the Three R philosophy requires this duplicity command run repeatedly. Create a simple shell script that wraps these environment variables and command invocation.
#!/bin/bash export AWS_ACCESS_KEY_ID=******************** export AWS_SECRET_ACCESS_KEY=**************************************** export PASSPHRASE=************ duplicity --name duply_documents --encrypt-sign-key **************** --include $HOME/Documents --exclude '**' $HOME s3+http://**********-backup-docs
Notice the addition of the PASSPHRASE variable. This allows duplicity to run without prompting for your GPG passphrase. Save this file somewhere in your home directory. It doesn’t have to be in your $PATH. Make sure the permissions are set to user read/write/execute only to protect the plain text GPG passphrase.
Now create a timer and service unit to run it daily.
$ cat $HOME/.config/systemd/user/backup.timer [Unit] Description=Run duplicity backup timer [Timer] OnCalendar=daily Unit=backup.service [Install] WantedBy=default.target $ cat $HOME/.config/systemd/user/backup.service [Service] Type=oneshot ExecStart=/home/link/backup.sh [Unit] Description=Run duplicity backup $ systemctl --user enable --now backup.timer Created symlink /home/link/.config/systemd/user/default.target.wants/backup.timer → /home/link/.config/systemd/user/backup.timer.
Conclusion
This article has described a manual process. But the flexibility in creating specific, customized backup targets is one of duplicity’s most powerful features. The duplicity man page has a lot more detail about various options. The next article will build on this one by creating backup profiles with duply, a wrapper program that makes the raw duplicity invocations easier.

Matěj Šmíd
Duplicity / Déja Dup works probably fine for small amounts of data (100s MB). I had used it for all my crucial data (few 100s GB) and it had struggled badly. Sometimes it haven’t managed to do an incremental backup overnight. The backup process is not optimized well: compression, encryption and upload are done sequentially so one can see that the CPU and network utilization is far from 100%.
I switched to Restic backup https://restic.github.io/ that’s build in Go and it’s incredibly fast. One of its design goal is that only the network or hard disk bandwidth should be the bottleneck. I would like to see the Restic backup to replace Duplicity in standard Gnome backup tool Déja Dup once.
c
Thanks, restic is a really awesome program, portable too.
pixel fairy
Left out a crucial step. backups must be done in two stages, sync and increment, “sync and inc”. otherwise, the data producer (your laptop) has access to the past backups, and thus malware or a mistake can erase that copy of your past. this may not seem like a big deal, thats why you also have an online copy, but an unknown infection would get around to all your backups.
the way around this is to make sure the data producer can not write to the past, by separating the steps. for example, rsync (or sneakernet) to another computer. then, from there, run duplicity to your external drive and offsite storage. that way, if you find out your laptops been compromised for 3 days, you only lose those 3 days. the key here is to make sure your data producer does not have access to whatever writes the past. so, in the above example, your laptop should not have ssh keys for admin access to the backup server.
many online backup services have this separation built in.
Lars Hupfeldt
Duplicity was made in the days of tape backup, using the incremental backup model and uses huge amounts of space. I switched to borgbackup https://borgbackup.readthedocs.io/en/stable/ and have not looked back.
Cody
From their website:
‘EXPECT THAT WE WILL BREAK COMPATIBILITY REPEATEDLY WHEN MAJOR RELEASE NUMBER CHANGES (like when going from 0.x.y to 1.0.0 or from 1.x.y to 2.0.0).
NOT RELEASED DEVELOPMENT VERSIONS HAVE UNKNOWN COMPATIBILITY PROPERTIES.
THIS IS SOFTWARE IN DEVELOPMENT, DECIDE YOURSELF WHETHER IT FITS YOUR NEEDS.’
That’s pretty scary for backup software, don’t you think? Not my data of course but backup and restore is critical and you’re relying on unstable (unstable in the sense of not a ‘stable release’, of course) software. Curious.
Lars Hupfeldt
In reality it is very stable and performs much better than duplicity. I would expect software that changes major version to not be backwards compatible (that is what the major version change implies). Pledging to be always backwards compatible leads to a code base which quickly becomes much harder to maintain, meaning slower progress with new features and/or higher risk of bugs.
The only issue I have experienced is the need to manually remove a stale lock file. This happened to me only when I killed the backup process while playing around with the configuration.
Cody
And don’t forget to have a disaster recovery policy including testing backup and restore (regularly).
And I beg to differ on not backing up source code only if it’s not under revision control. What if you’ve not committed (or in the case of git committed and pushed)? What if it’s on the same system? What if .. well there are a lot of ‘what if’ questions and not backing up source code is frankly stupid or if nothing else naïve.
And define data ‘you created’. What about generated content? What about non-standard locations of data (re ~/Documents etc.) ? (And even things like /opt or for some like me /srv …) It might be a good starting point but only a starting point. It should also be noted that even if you downloaded it from the Internet maybe when you need it next it’s no longer available and wasn’t archived anywhere else.
You should also of course separate /home and other volumes and arguably all of /home should be backed up (though you could of course have exclusion locations under /home or anywhere else for that matter). You might also consider /root as another option.
No comment on the specific backup systems since I’ve not used them.
Ananda Amatya
I am having problem with using duplicity.
In the code below what is s3+http://**********-backup-docs?
duplicity –dry-run –name duply_documents –encrypt-sign-key **************** –include $HOME/Documents –exclude ‘**’ $HOME s3+http://**********-backup-docs
I keep getting error message:
Your account is not signed up for the S3 service. You must sign up before you can use S3.63925ACDBB28ED2C1vvggAOjx46sGI1WEsX8TEz1xblDWXd/2CbD2gxF3vonFmI+iCFeNGjVAKvRYFZTx11Rhv939MY=
Thanks
Ananda