



This article is part of a short series that introduces Kubernetes. This beginner-oriented series covers some higher level concepts and gives examples of using Kubernetes on Fedora.
The information technology world changes daily, and the demands of building scalable infrastructure become more important. Containers aren’t anything new these days, and have various uses and implementations. But what about building scalable, containerized applications? By itself, Docker and other tools don’t quite cut it, as far as building the infrastructure to support containers. How do you deploy, scale, and manage containerized applications in your infrastructure? This is where tools such as Kubernetes comes in. Kubernetes is an open source system that automates deployment, scaling, and management of containerized applications. Kubernetes was originally developed by Google before being donated to the Cloud Native Computing Foundation, a project of the Linux Foundation. This article gives a quick precursor to what Kubernetes is and what some of the buzzwords really mean.
What is Kubernetes?
Kubernetes simplifies and automates the process of deploying containerized applications at scale. Just like Ansible orchestrates software, Kubernetes orchestrates deploying infrastructure that supports the software. There are various “layers of the cake” that make Kubernetes a strong solution for building resilient infrastructure. It also assists with making systems that can grow at scale. If your application has increasing demands such as higher traffic, Kubernetes helps grow your environment to support increasing demands. This is one reason why Kubernetes is helpful for building long-term solutions for complex problems (even if it’s not complex… yet).
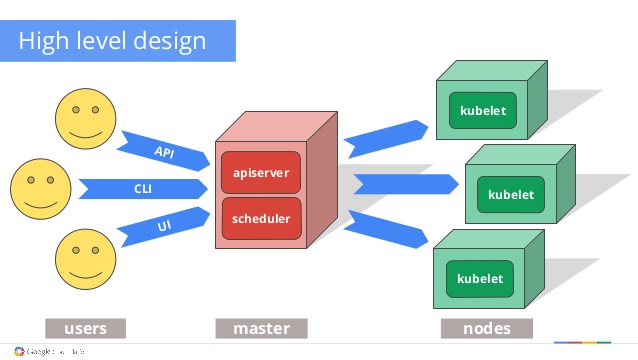
Kubernetes: The high level design. Daniel Smith, Robert Bailey, Kit Merker.
At a high level overview, imagine three different layers.
- Users: People who deploy or create containerized applications to run in your infrastructure
- Master(s): Manages and schedules your software across various other machines, for example in a clustered computing environment
- Nodes: Various machines to support the application, called kubelets
These three layers are orchestrated and automated by Kubernetes. One of the key pieces of the master (not included in the visual) is etcd. etcd is a lightweight and distributed key/value store that holds configuration data. Each node, or kubelet, can access this data in etcd through a HTTP/JSON API interface. The components of communication between master and node such as etcd are explained in the official documentation.
Another important detail not shown in the diagram is that you might have many masters. In a high-availability (HA) set-up, you can keep your infrastructure resilient by having multiple masters in case one happens to go down.
Terminology
It’s important to understand the concepts of Kubernetes before you start to play around with it. There are many core concepts in Kubernetes, such as services, volumes, secrets, daemon sets, and jobs. However, this article explains four that are helpful for the next exercise of building a mini Kubernetes cluster. The four concepts are pods, labels, replica sets, and deployments.
Pods
If you imagine Kubernetes as a Lego® castle, pods are the smallest block you can pick out. By themselves, they are the smallest unit you can deploy. The containers of an application fit into a pod. The pod can be one container, but it can also be as many as needed. Containers in a pod are unique since they share the Linux namespace and aren’t isolated from each other. In a world before containers, this would be similar to running an application on the same host machine.
When the pods share the same namespace, all the containers in a pod:
- Share an IP address
- Share port space
- Find each other over localhost
- Communicate over IPC namespace
- Have access to shared volumes
But what’s the point of having pods? The main purpose of pods is to have groups of “helping” containers on the same namespace (co-located) and integrated together (co-managed) along with the main application container. Some examples might be logging or monitoring tools that check the health of your application, or backup tools that act when certain data changes.
In the big picture, containers in a single pod are always scheduled together too. However, Kubernetes doesn’t automatically reschedule them to a new node if the node dies (more on this later).
Labels
Labels are a simple but important concept in Kubernetes. Labels are key/value pairs attached to objects in Kubernetes, like pods. They let you specify unique attributes of objects that actually mean something to humans. You can attach them when you create an object, and modify or add them later. Labels help you organize and select different sets of objects to interact with when performing actions inside of Kubernetes. For example, you can identify:
- Software releases: Alpha, beta, stable
- Environments: Development, production
- Tiers: Front-end, back-end
Labels are as flexible as you need them to be, and this list isn’t comprehensive. Be creative when thinking of how to apply them.
Replica sets
Replica sets are where some of the magic begins to happen with automatic scheduling or rescheduling. Replica sets ensure that a number of pod instances (called replicas) are running at any moment. If your web application needs to constantly have four pods in the front-end and two in the back-end, the replica sets are your insurance that number is always maintained. This also makes Kubernetes great for scaling. If you need to scale up or down, change the number of replicas.
When reading about replica sets, you might also see replication controllers. They are somewhat interchangeable, but replication controllers are older, semi-deprecated, and less powerful than replica sets. The main difference is that sets work with more advanced set-based selectors — which goes back to labels. Ideally, you won’t have to worry about this much today.
Even though replica sets are where the scheduling magic happens to help make your infrastructure resilient, you won’t actually interact with them much. Replica sets are managed by deployments, so it’s unusual to directly create or manipulate replica sets. And guess what’s next?
Deployments
Deployments are another important concept inside of Kubernetes. Deployments are a declarative way to deploy and manage software. If you’re familiar with Ansible, you can compare deployments to the playbooks of Ansible. If you’re building your infrastructure out, you want to make sure it is easily reproducible without much manual work. Deployments are the way to do this.
Deployments offer functionality such as revision history, so it’s always easy to rollback changes if something doesn’t work out. They also manage any updates you push out to your application, and if something isn’t working, it will stop rolling out your update and revert back to the last working state. Deployments follow the mathematical property of idempotence, which means you define your specs once and use them many times to get the same result.
Deployments also get into imperative and declarative ways to build infrastructure, but this explanation is a quick, fly-by overview. You can read more detailed information in the official documentation.
Installing on Fedora
If you want to start playing with Kubernetes, install it and some useful tools from the Fedora repositories.
sudo dnf install kubernetes
This command provides the bare minimum needed to get started. You can also install other cool tools like cockpit-kubernetes (integration with Cockpit) and kubernetes-ansible (provisioning Kubernetes with Ansible playbooks and roles).
Learn more about Kubernetes
If you want to read more about Kubernetes or want to explore the concepts more, there’s plenty of great information online. The documentation provided by Kubernetes is fantastic, but there are also other helpful guides from DigitalOcean and Giant Swarm. The next article in the series will explore building a mini Kubernetes cluster on your own computer to see how it really works.
Questions, Kubernetes stories, or tips for beginners? Add your comments below.

Audun Nes
I attended Kubernetes advanced training this week, and think this article was a nice summary of the key concept.
Two features that could have made it into this article IMHO are services and ingress, but perhaps that could be inspiration for a follow-up article?
Justin W. Flory
Thanks for the feedback, Audun! I agree that Services and Ingresses would be good topics to cover for additional pieces. I’ll try to cover these bits in an upcoming article (there’s a few more parts to the series yet to come). Thanks for the suggestion!
Jason
Great to to see an article on this topic. I started with docker a few years ago. Hand rolled a custom CI/CD process , monitoring etc. Started using Kube last year and would never go back to that again. Currently using custom AMIs in AWS to run clusters.
I run Fedora and didn’t even know there were prepacked rpms for Kube. I hope these end up in the Red Hat and Centos repos, or maybe I might even give Fedora Atomic a go. (I do prefer Calico to Flannel though) .
Justin W. Flory
Thanks for reading, Jason! Glad you enjoyed it. And yes, there’s definitely RPMs available! CentOS and RHEL also definitely have support for Kubernetes. Best of luck in some of your experimentation. 🙂
Mark Jeffery
Apologies for being pedantic , I think there’s a typo :
Under Replica Sets.
“If your web application needs to constantly have four pods in the back-end and two in the back-end,”
Paul W. Frields
@Mark: Fixed, thanks!
hos7ein
tnx , nice article
Matt
Thank you for the overview. I look forward to reading the rest of the series.
I found an extra “be” in the second to last sentence of the Pods section:
Justin W. Flory
Glad you’re enjoying the series, Matt. 🙂 Feel free to check out the next part here: https://fedoramag.wpengine.com/minikube-kubernetes/
And thanks for catching that typo! I just fixed it now.
Anthony Chow
I did “dnf install kubernetes” on my Fedora 25 desktop. Is this similar to minikube? Do I start the master and slaves on this same machine? thanks for the info.
Anthony Chow
I found this myself and is this the correct link?
https://kubernetes.io/docs/getting-started-guides/fedora/fedora_manual_config/