





This article is part of a series of articles that takes a closer look at Btrfs. This is the default filesystem for Fedora Workstation and Fedora Silverblue since Fedora Linux 33.
Introduction
Filesystems are one of the foundations of modern computers. They are an essential part of every operating system and they usually work unnoticed. However, modern filesystems such as Btrfs offer many great features that make working with computers more convenient. Next to other things they can, for example, transparently compress your files for you or build a solid foundation for incremental backups.
This article gives you a high-level overview of how the Btrfs filesystem works and some of the features it has. It will not go into much technical detail nor look at the implementation. More detailed explanations of some highlighted features follow in later articles of this series.
What is a filesystem?
If you’ve heard before how filesystems work on the most basic level, then this isn’t new to you and you can skip to the next section. Otherwise, read ahead for a short introduction into what makes a filesystem in the first place.
In simple terms, a filesystem allows your PC to find the data that it stores on disk. This sounds like a trivial task, but in essence any type of non-volatile storage device today (such as HDDs, SSDs, SD cards, etc…) is still mostly what it was back in 1970 when PCs were being invented: A (huge) collection of storage blocks.
Blocks are the most granular addressable storage unit. Every file on your PC is stored across one or more blocks. A block is typically 4096 bytes in size. This depends on the hardware you have and the software (i.e. the filesystem) on top of it.
Filesystems allow us to find the contents of our files from the vast amount of available storage blocks. This is done via so-called inodes. An inode contains information about a file in a specially formatted storage block. This includes the file’s size, where to find the storage blocks that make up the file contents, its access rules (i.e. who can read, write or execute the file) and much more.
Below is an example of what this looks like:

The structure of an inode has big implications on a filesystem’s capabilities, so it is one of the central datastructures for any file system. For this reason every filesystem has its own inode structure. If you want to know more about this, have a look at the inode structure of the Btrfs filesystem linked below [1]. For a more detailed explanation of what the individual fields mean, you can refer to the inode structure of the ext4 filesystem [2].
Copy-on-Write filesystems
One of the outstanding features of Btrfs, compared to ext4, for example, is that it is a CoW (Copy-on-Write) filesystem. When a file is changed and written back to disk, it intentionally is not written back to where it was before. Instead, it is copied and stored in an entirely new location on disk. In this sense, it may be simpler to think of CoW as a kind of “redirection”, because the file write is redirected to different storage blocks.
This may sound wasteful, but in practice it isn’t. This is because the modified data must be written back to the disk in any case, regardless of how the filesystem works. Btrfs merely makes sure that the data is written to previously unoccupied blocks, so the old data remains intact. The only real drawback is that this behavior can lead to file fragmentation quicker than on other filesystems. In regular desktop usage scenarios it is unlikely you will notice a difference.
What is the advantage of CoW? In simple terms: a history of the modified and edited files can be kept. Btrfs will keep the references to the old file versions (inodes) somewhere they can be easily accessed. This reference is a snapshot: An image of the filesystem state at some point in time. This will be the topic of a separate article in this series, so it will be left at that for now.
Beyond keeping file histories, CoW filesystems are always in a consistent state, even if a previous filesystem transaction (like writing to a file) didn’t complete due to e.g. power loss. That is because filesystem metadata updates are also CoW: The file system itself is never overwritten, so an interruption can’t leave it in a partially written state
Copy-on-Write for files
You can think of filenames as pointers to the inodes of the file they belong to. Upon writing to a file, Btrfs creates a copy of the modified file content (the data), along with a new inode (the metadata), and then makes your filename point to this new inode. The old inode remains untouched. Below you see another hypothetical example to illustrate this:
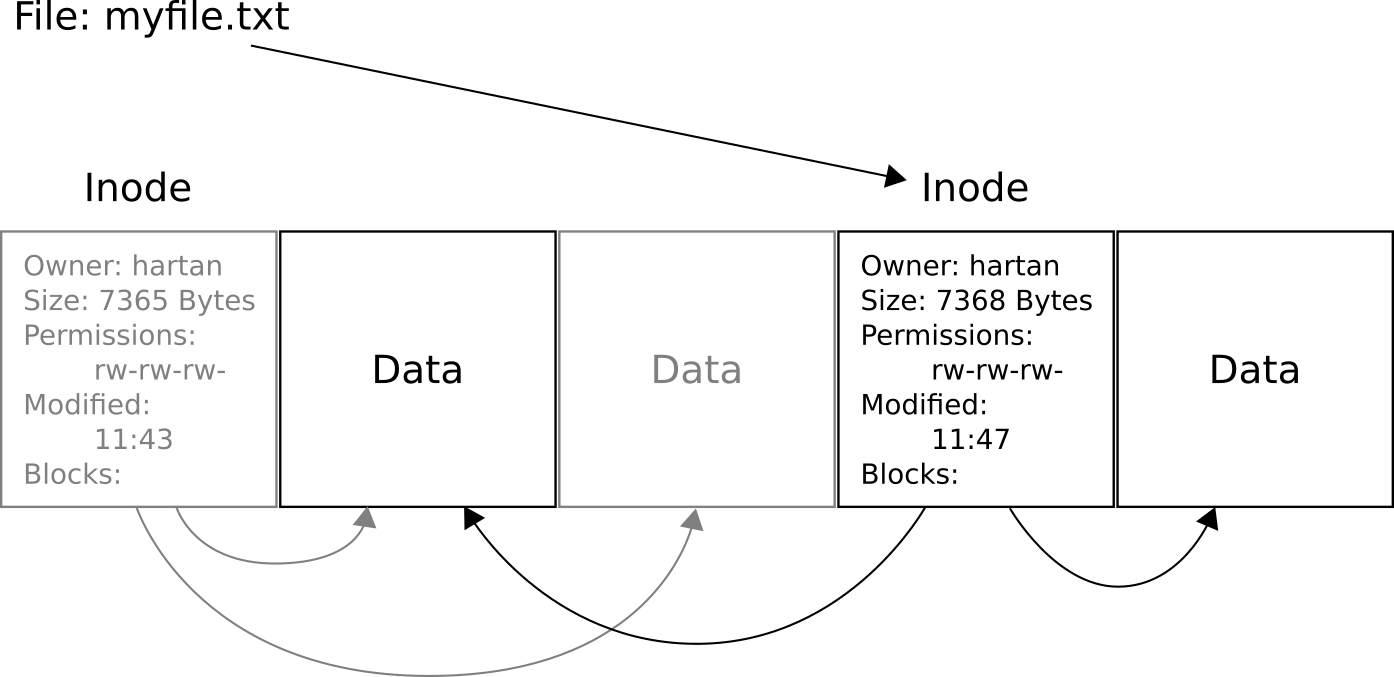
Here “myfile.txt” has had three bytes appended. A traditional filesystem would have updated the “Data” block in the middle to contain the new contents. A CoW filesystem keeps the old blocks intact (greyed out) and writes (copies) changed data and metadata somewhere new. It is important to note that only changed data blocks are copied, and not the whole file.
If there are no more unused blocks to write new contents to, Btrfs will reclaim space from data blocks occupied by old file versions (Unless they are part of a snapshot, see later article in this series).
Copy-on-Write for folders
From a filesystem’s point of view, a folder is a special type of file. In contrast to regular files, the filesystem interprets the underlying contents directly. A folder has some metadata associated with it (an inode, as seen for files above) that governs access permissions or modification time. In the simplest case, the data stored in a folder (so called “directory entries”) is a list of references to inodes, where each inode is in turn another file or folder. However, modern filesystems store at least a filename, together with a reference to an inode of the file in question, in a directory entry.
Earlier it was pointed out that writing to a file creates a copy of the previous inode and modifies the contents accordingly. In essence, this yields a new inode that isn’t related to its predecessor. To make the modified file show up in the filesystem, all the directory entries containing a reference to it are updated as well.
This is a recursive process! Since a folder is itself a file with an inode, modifying any of its folder entries creates a new inode for the folder file. This recursion occurs all the way up the filesystem tree, until it arrives at the filesystem root.
As a consequence, as long as a reference is kept to any of the old directories and they are not deleted or overwritten, the filesystem tree can be traversed in it’s previous state. This, again, is exactly what snapshots do.
What to expect in future articles
Btrfs is more than just a CoW filesystem. It aims to implement “advanced features while also focusing on fault tolerance, repair and easy administration” (See [3]). Future articles of this series will have a look at these features in particular:
- Subvolumes – Filetrees within your filetree
- Snapshots – Going back in time
- Compression – Transparently saving storage space
- Qgroups – Limiting your filesystem size
- RAID – Replace your mdadm configuration
This is by far not an exhaustive list of Btrfs features. If you want the full overview of available features, check out the Wiki [4] and Docs [3].
Conclusion
I hope that I managed to whet your appetite for getting to know your PC filesystem. If you have questions so far, please leave a comment about what you come up with so they can be discussed in future articles. In the meantime, feel free to study the linked resources in the text. If you stumble over a Btrfs feature that you find particularly intriguing, please add a comment below, too. If there’s enough interest in a particular topic, maybe I’ll add an article to the series. See you in the next article!
Sources
[1]: https://btrfs.wiki.kernel.org/index.php/Data_Structures#btrfs_inode_item
[2]: https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Inode_Table
[3]: https://btrfs.readthedocs.io/en/latest/Introduction.html
[4]: https://btrfs.wiki.kernel.org/index.php/Main_Page

Oscar
I’d like Stratis could be a real competitor in a near future
Chris Murphy
Congrats on this first article, Andreas! Good work! Looking forward to reading the rest of the series – keep writing!
Simon
Very informative and clear! I’m looking forward to further articles about btrfs.
lol
“For a more detailed explanation of what the individual fields mean, you can refer to the inode structure of the ext4 filesystem” …
John
You’ve got a great writing style! Thanks for sharing!
Matthew
This article is fantastic, love the style and the explanation is great! I’m looking forward to the rest of the series!
Benjamin
Nice intro! now I need the rest of this series 😉
Chamseddine
You will be surprised to know XFS or Ext4 do not require defragmentation.
Heliosstyx
A very good description of the btrfs concepts and similar files-ystems. Perhaps can you write also an article about btrfs automated clean-up mechanisms? It would help newcomers to administer btrfs in a right way. Thank you.
Andreas Hartmann
Thank you for the suggestion!
I’m not sure I understand what you mean here, could you try to explain a little more? If you’re referring to the automated removal of “old file copies” (files that aren’t referenced any longer), that is automatically handled by Btrfs. There is no manual intervention needed.
David Brownburg
Nice job!
Satheesaran
Also, it would be good to know the advantage of using BTRFS over XFS, and the reason why Fedora chose to use BTRFS
Benjamin
If I recal correctly, XFS partition are not shrinkable. While I’m fine with it on a data disk (and it’s probably the best for a media server!), I don’t want an unshrinkable partition near a disk that hold boot and/or home partition! It had already bite me in the past, and it being the defaut on a distro whould be a dealbreaker for me.
C.
XFS is definitely not shrinkable. It also doesn’t have file checksumming, so bit rot can be an issue.
Overall, XFS is a decent filesystem, but btrfs just is better than it in many ways. btrfs brings with it built in compression (lzo, zstd), but you can use a utility like duperemove for offline deduplication, and the nice thing about how dedupe is implemented in btrfs is that it requires no additional RAM. Yes, the dedupe process will take up memory when running, but the btrfs filesystem will not need RAM to decode dedupe tables like ZFS and VDO do.
People bash btrfs, but Synology has been using it as their main filesystem in their low-midrange NAS appliances, implemented on top of md-raid. If there were any show-stopping bugs, people would be screaming everywhere.
The biggest reason why btrfs is stable these days is that Facebook/Meta has thrown a lot of development effort into ensuring the filesystem can handle petabytes of their own data, likely NoSQL based, and a filesystem that handles this needs to be able to have a lot of intrinsic data protection measures like file checksumming, COW, online scrubbing, snapshots, etc.
b
We have many use-cases but btrfs isn’t a ZFS Holy Grail. To be clear and nuanced, there are different risk tolerances and expectations between client machines (grandma’s laptop vs. developer machine), stateless web services, stateful database servers, and stateful specialized loads. We have 10^5-ish Linux desktop users where Fedora (N-1) is the only officially-supported choice.
At home, I use AlmaLinux 9 + XFS on mdraid on my NAS because I had a terrible experience with ZFS (ZoL). It was permanently read-only and there was zero support. That’s what happens with ripping production code out of Solaris, trying to transplant it, and work without corporate backing.
Btrfs and ZoL are never going to be production stable because they don’t get used in critical corporate infrastructure and/or mass market use the ways Ext4, XFS, NTFS, APFS, F2FS, and Solaris ZFS did.
One can live on the bleeding edge with fancy features but they should expect to enjoy fixing it themselves when it breaks. If you want (data + metadata) integrity, snapshots, or encryption, do it at the block device level. It’s not as fine-grained as distributed, ft, ha fses but it’s simpler and is fs-independent. The key with block device snapshots (and most backup/restore operations) is orchestrating quiescence of stateful workloads, flushing fs buffers, and pausing any scrub-/repair-type crons.
Bernd
Thanks for the article! I’m still on a continuous upgrade from before Fedora switched to btrfs, so I’m wondering, how does this play together with LVM? Or are these two completely separate things?
Gregory Bartholomew
There is a “Btrfs on LVM” section at the end of this earlier article.
Edier
Wow thank you. I want to read all the BTRFS series that you will write here.
I always wanted to know technical features of this filesystem
Renich Bon Ćirić
Very informative. Thanks a ton! 😀
Mr Leslie Satenstein, Montreal,Que
Well done Andreas. Btrfs is today a great file system. I use it as a preference file system for Fedora (gnome and kde) and for another distribution that heavily promotes it’s use.
I also discovered a utility that collects disposed blocks, as otherwise, the partition could after some heavy file creation and deletion, create many “discarded blocks” that are no loner of interest.
I am looking forward to your follow up presentation
Audun Nes
Thanks for a very well written article. I’ve heard about btrfs for years, but never looked into how it worked. It was also news to me that btrfs is now the default filesystem on Fedora Workstation. I hadn’t noticed the change.
Spunkie
I’m interested to get to the snapshot and qgroup posts.
I only know qgroups as that thing that would completely freeze my machine every hour when making a snapshot. I had to outright disable qgroups system wide to make it workable and even after the bug stuck around in timeshift for over a year they eventually ripped out an entire feature set rather than fixing the underlying qgroups issue.
Also, when I made the switch to linux, I was so excited about btrfs snapshots + timeshift-autosnap-manjaro + grub, and it turned out to be exactly the kind of easy to use pre OS boot magic safety net I imagined with snapshots.
But I’ve since switched to arch with systemd-boot and haven’t found a replacement yet. 🥲
mlll
Pretty good writeup, it’d be great that seeing this series continued.
Darvond
How about things such as “Scheduling a filesystem check”?
“Verifying data integrity”?
Stuart Gathman
man btrfs check
Stuart Gathman
“CoW filesystems are always in a consistent state, even if a previous filesystem transaction (like writing to a file) didn’t complete due to e.g. power loss. That is because filesystem metadata updates are also CoW: The file system itself is never overwritten, so an interruption can’t leave it in a partially written state.”
This is not actually true – because the disk drive controller doesn’t necessarily write blocks to the media in the order they were sent to the drive controller.
To make it so, you can disable write cache on the drive at a loss of performance. Or buy drives with battery backed controller memory so it can finish queued writes on system power loss ($$$).
There are also write cache algorithms that preserve write ordering (such as used by DRBR queue software).
b
Don’t conflate uncommitted dirty data loss with previously stored data loss/corruption from partial writes. Most CoW and log-structured fses are immune to the latter while some old-school fses aren’t to the former. If the power goes out, a battery fails, the kernel panics, or a meteor hits, there are edge-cases of data loss that cannot be prevented. It’s the behavior of partial writes that is the make-or-break. ZFS supposedly wrote data blocks to preferring unallocated space and wrote metadata last in such a way that it was crash fail-safe.
klaatu
This is the clearest article on BtrFS I’ve read. Thank you for this.
Buyer
Thanks for the article.
I know about BTRFS and ZFS (ZoL in particular) more than a decade.
I use ZFS on my NAS since 2011.
What I missing in ZFS are reflinks and a real O_DIRECT support (WIP now).
IMHO the main showstopper for BTRFS usage on the NAS is absent of production ready RAID 5 and 6 support.
Stuart Gathman
mdraid has been production ready for many years now, and is filesystem independent. I recommend layering LVM on top of mdraid with classic (NOT “thin”) volumes for btrfs. This is because LVs work much better with KVM, allow easy resizing, and classic LV performance with no active snapshots is basically equivalent to a partition.
Buyer
Many different layers are less handy than ZFS “all in one”.
Sure both has a pros&cons. E.g. ZFS provides “send/receive” feature which is not possible with stack of mdraid or LVM and FS above.
Kristian
Sorry to be the odd one out amongst all the experts above, on top of being not a pro of filesystem. Reading the above sentence out loud, I still need more information for clarification. I’m still wondering whether it’s only the modified part of a file content that is copied. Then, the modified part(s) of the file content (new block Z) is kept along with the original (unmodified) file content (block Y) metadata-wise in a new inode. The filename then points to this new inode, which refers back to the original unmodified file and the modified portion of the file. Unless, I’m completely of track…
Andreas Hartmann
No need to apologize, sorry if I confused you!
I think you got it right, yes. All the parts of the file that aren’t changed aren’t copied either. It’s important to keep in mind that the old inode is kept, too, and only the old inode points to block Y from your example. The new inode points to Z. All the rest of the file contents (data blocks A-X) is pointed to by both inodes.
Anders Ö
Waiting for more good write-ups on btrfs!
gianluca
when f37 comes out i try to install a clean revision with btrfs, but i remember was slow compare to ext4…