




Fedora CoreOS is a lightweight, secure operating system optimized for running containerized workloads. A YAML document is all you need to describe the workload you’d like to run on a Fedora CoreOS server.
This is wonderful for a single server, but how would you describe a fleet of cooperating Fedora CoreOS servers? For example, what if you wanted a set of servers running load balancers, others running a database cluster and others running a web application? How can you get them all configured and provisioned? How can you configure them to communicate with each other? This article looks at how Terraform solves this problem.
Getting started
Before you start, decide whether you need to review the basics of Fedora CoreOS. Check out this previous article on the Fedora Magazine:
Terraform is an open source tool for defining and provisioning infrastructure. Terraform defines infrastructure as code in files. It provisions infrastructure by calculating the difference between the desired state in code and observed state and applying changes to remove the difference.
HashiCorp, the company that created and maintains Terraform, offers an RPM repository to install Terraform.
sudo dnf config-manager --add-repo \ https://rpm.releases.hashicorp.com/fedora/hashicorp.repo sudo dnf install terraform
To get yourself familiar with the tools, start with a simple example. You’re going to create a single Fedora CoreOS server in AWS. To follow along, you need to install awscli and have an AWS account. awscli can be installed from the Fedora repositories and configured using the aws configure command
sudo dnf install -y awscli aws configure
Please note, AWS is a paid service. If executed correctly, participants should expect less than $1 USD in charges, but mistakes may lead to unexpected charges.
Configuring Terraform
In a new directory, create a file named config.yaml. This file will hold the contents of your Fedore CoreOS configuration. The configuration simply adds an SSH key for the core user. Modify the authorized_ssh_key section to use your own.
variant: fcos
version: 1.2.0
passwd:
users:
- name: core
ssh_authorized_keys:
- "ssh-ed25519 AAAAC3....... user@hostname"
Next, create a file main.tf to contain your Terraform specification. Take a look at the contents section by section. It begins with a block to specify the versions of your providers.
terraform {
required_providers {
ct = {
source = "poseidon/ct"
version = "0.7.1"
}
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
Terraform uses providers to control infrastructure. Here it uses the AWS provider to provision EC2 servers, but it can provision any kind of AWS infrastructure. The ct provider from Poseidon Labs stands for config transpiler. This provider will transpile Fedora CoreOS configurations into Ignition configurations. As a result, you do not need to use fcct to transpile your configurations. Now that your provider versions are specified, initialize them.
provider "aws" {
region = "us-west-2"
}
provider "ct" {}
The AWS region is set to us-west-2 and the ct provider requires no configuration. With the providers configured, you’re ready to define some infrastructure. Use a data source block to read the configuration.
data "ct_config" "config" {
content = file("config.yaml")
strict = true
}
With this data block defined, you can now access the transpiled Ignition output as data.ct_config.config.rendered. To create an EC2 server, use a resource block, and pass the Ignition output as the user_data attribute.
resource "aws_instance" "server" {
ami = "ami-0699a4456969d8650"
instance_type = "t3.micro"
user_data = data.ct_config.config.rendered
}
This configuration hard-codes the virtual machine image (AMI) to the latest stable image of Fedora CoreOS in the us-west-2 region at time of writing. If you would like to use a different region or stream, you can discover the correct AMI on the Fedora CoreOS downloads page.
Finally, you’d like to know the public IP address of the server once it’s created. Use an output block to define the outputs to be displayed once Terraform completes its provisioning.
output "instance_ip_addr" {
value = aws_instance.server.public_ip
}
Alright! You’re ready to create some infrastructure. To deploy the server simply run:
terraform init # Installs the provider dependencies terraform apply # Displays the proposed changes and applies them
Once completed, Terraform prints the public IP address of the server, and you can SSH to the server by running ssh core@{public ip here}. Congratulations — you’ve provisioned your first Fedora CoreOS server using Terraform!
Updates and immutability
At this point you can modify the configuration in config.yaml however you like. To deploy your change simply run terraform apply again. Notice that each time you change the configuration, when you run terraform apply it destroys the server and creates a new one. This aligns well with the Fedora CoreOS philosophy: Configuration can only happen once. Want to change that configuration? Create a new server. This can feel pretty alien if you’re accustomed to provisioning your servers once and continuously re-configuring them with tools like Ansible, Puppet or Chef.
The benefit of always creating new servers is that it is significantly easier to test that newly provisioned servers will act as expected. It can be much more difficult to account for all of the possible ways in which updating a system in place may break. Tooling that adheres to this philosophy typically falls under the heading of Immutable Infrastructure. This approach to infrastructure has some of the same benefits seen in functional programming techniques, namely that mutable state is often a source of error.
Using variables
You can use Terraform input variables to parameterize your infrastructure. In the previous example, you might like to parameterize the AWS region or instance type. This would let you deploy several instances of the same configuration with differing parameters. What if you want to parameterize the Fedora CoreOS configuration? Do so using the templatefile function.
As an example, try parameterizing the username of your user. To do this, add a username variable to the main.tf file:
variable "username" {
type = string
description = "Fedora CoreOS user"
default = "core"
}
Next, modify the config.yaml file to turn it into a template. When rendered, the ${username} will be replaced.
variant: fcos
version: 1.2.0
passwd:
users:
- name: ${username}
ssh_authorized_keys:
- "ssh-ed25519 AAAAC3....... user@hostname"
Finally, modify the data block to render the template using the templatefile function.
data "ct_config" "config" {
content = templatefile(
"config.yaml",
{ username = var.username }
)
strict = true
}
To deploy with username set to jane, run terraform apply -var=”username=jane”. To verify, try to SSH into the server with ssh jane@{public ip address}.
Leveraging the dependency graph
Passing variables from Terraform into Fedora CoreOS configuration is quite useful. But you can go one step further and pass infrastructure data into the server configuration. This is where Terraform and Fedora CoreOS start to really shine.
Terraform creates a dependency graph to model the state of infrastructure and to plan updates. If the output of one resource (e.g the public IP address of a server) is passed as the input of another service (e.g the destination in a firewall rule), Terraform understands that changes in the former require recreating or modifying the later. If you pass infrastructure data into a Fedora CoreOS configuration, it will participate in the dependency graph. Updates to the inputs will trigger creation of a new server with the new configuration.
Consider a system of one load balancer and three web servers as an example.
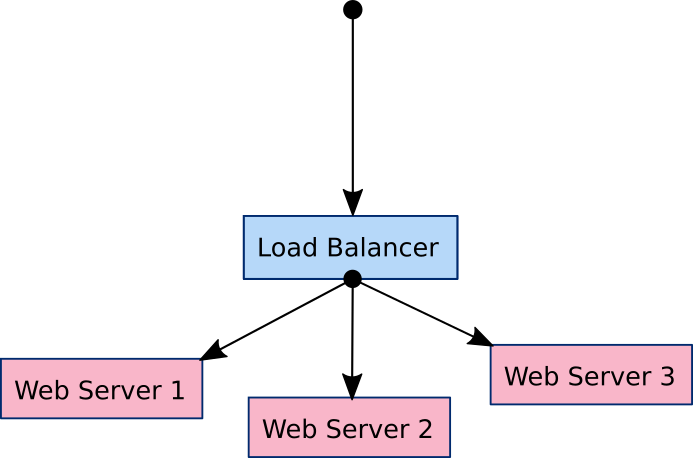
The goal is to configure the load balancer with the IP address of each web server so that it can forward traffic to them.
Web server configuration
First, create a file web.yaml and add a simple Nginx configuration with a templated message.
variant: fcos
version: 1.2.0
systemd:
units:
- name: nginx.service
enabled: true
contents: |
[Unit]
Description=Nginx Web Server
After=network-online.target
Wants=network-online.target
[Service]
ExecStartPre=-/bin/podman kill nginx
ExecStartPre=-/bin/podman rm nginx
ExecStartPre=/bin/podman pull nginx
ExecStart=/bin/podman run --name nginx -p 80:80 -v /etc/nginx/index.html:/usr/share/nginx/html/index.html:z nginx
[Install]
WantedBy=multi-user.target
storage:
directories:
- path: /etc/nginx
files:
- path: /etc/nginx/index.html
mode: 0444
contents:
inline: |
<html>
<h1>Hello from Server ${count}</h1>
</html>
In main.tf, you can create three web servers using this template with the following blocks:
data "ct_config" "web" {
count = 3
content = templatefile(
"web.yaml",
{ count = count.index }
)
strict = true
}
resource "aws_instance" "web" {
count = 3
ami = "ami-0699a4456969d8650"
instance_type = "t3.micro"
user_data = data.ct_config.web[count.index].rendered
}
Notice the use of count = 3 and the count.index variable. You can use count to make many copies of a resource. Here, it creates three configurations and three web servers. The count.index variable is used to pass the first configuration to the first web server and so on.
Load balancer configuration
The load balancer will be a basic HAProxy load balancer that forwards to each server. Place the configuration in a file named lb.yaml:
variant: fcos
version: 1.2.0
systemd:
units:
- name: haproxy.service
enabled: true
contents: |
[Unit]
Description=Haproxy Load Balancer
After=network-online.target
Wants=network-online.target
[Service]
ExecStartPre=-/bin/podman kill haproxy
ExecStartPre=-/bin/podman rm haproxy
ExecStartPre=/bin/podman pull haproxy
ExecStart=/bin/podman run --name haproxy -p 80:8080 -v /etc/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro haproxy
[Install]
WantedBy=multi-user.target
storage:
directories:
- path: /etc/haproxy
files:
- path: /etc/haproxy/haproxy.cfg
mode: 0444
contents:
inline: |
global
log stdout format raw local0
defaults
mode tcp
log global
option tcplog
frontend http
bind *:8080
default_backend http
backend http
balance roundrobin
%{ for name, addr in servers ~}
server ${name} ${addr}:80 check
%{ endfor ~}
The template expects a map with server names as keys and IP addresses as values. You can create that using the zipmap function. Use the ID of the web servers as keys and the public IP addresses as values.
data "ct_config" "lb" {
content = templatefile(
"lb.yaml",
{
servers = zipmap(
aws_instance.web.*.id,
aws_instance.web.*.public_ip
)
}
)
strict = true
}
resource "aws_instance" "lb" {
ami = "ami-0699a4456969d8650"
instance_type = "t3.micro
user_data = data.ct_config.lb.rendered
}
Finally, add an output block to display the IP address of the load balancer.
output "load_balancer_ip" {
value = aws_instance.lb.public_ip
}
All right! Run terraform apply and the IP address of the load balancer displays on completion. You should be able to make requests to the load balancer and get responses from each web server.
$ export LB={{load balancer IP here}}
$ curl $LB
<html>
<h1>Hello from Server 0</h1>
</html>
$ curl $LB
<html>
<h1>Hello from Server 1</h1>
</html>
$ curl $LB
<html>
<h1>Hello from Server 2</h1>
</html>
Now you can modify the configuration of the web servers or load balancer. Any changes can be realized by running terraform apply once again. Note in particular that any change to the web server IP addresses will cause Terraform to recreate the load balancer (changing the count from 3 to 4 is a simple test). Hopefully this emphasizes that the load balancer configuration is indeed a part of the Terraform dependency graph.
Clean up
You can destroy all the infrastructure using the terraform destroy command. Simply navigate to the folder where you created main.tf and run terraform destroy.
Where next?
Code for this tutorial can be found at this GitHub repository. Feel free to play with examples and contribute more if you find something you’d love to share with the world. To learn more about all the amazing things Fedora CoreOS can do, dive into the docs or come chat with the community. To learn more about Terraform, you can rummage through the docs, checkout #terraform on freenode, or contribute on GitHub.

David Bertrand
is terraform only for fedora coreOS and aws or can it be used for other Fedora on dedicated server?
Nathan Smith
Good question! Terraform can be used any type of operating system and any type of cloud provider. Terraform can also provision a lot more than just servers. You can browse the providers on Terraform Registry here: https://registry.terraform.io/browse/providers
Nigel
I had to change authorized_ssh_keys => ssh_authorized_keys due to some yaml unmarshall error. This is really cool tutorial. Thanks!
Nathan Smith
Oops! Thanks for catching that. I’ll look into getting that corrected with the editors. I’m glad you enjoyed the article!
Gregory Bartholomew
I think I’ve made the requested correction. Let me know if I missed anything.
Jason
you can get the latest version of an AMI with the correct filters using a data lookup instead of hard coding the ID.
eg:
data “aws_ami” “latest_fedora_coreos” {
filter {
name = “name”
values = [“????”]
}
most_recent = true
owners = [????]
}
now you can reference it using:
data.aws_ami.latest_fedora_coreos.id
Nathan Smith
Nice! Thanks for sharing the snippet for that. To fill in the blanks, here is the block I use in my projects to grab the latest stable AMI:
data “aws_ami” “fcos” {
most_recent = true
owners = [“125523088429”]
filter {
name = “name”
values = [“fedora-coreos-“]
}
filter {
name = “description”
values = [“Fedora CoreOS stable“]
}
}
Ivan
So does it mean that Fedora CoreOS is not suitable to store data?
Nathan Smith
Fedora CoreOS is suitable for stateful application, but it takes a little more consideration. I’ve been considering writing a second article as a follow up to describe that. The gist is that you need separate the data from the operating system in a separate disk. While operating system is reprovisioned you want to always attach the same data disk. The disk and filesystem sections of the FCCT specification are idempotent. This means that if they aren’t in the right format they will be formatted and configured, but if they are then they won’t be touched. This allows you to keep your data between reprovisions of your operating system.
Ivan
Cool! I am intrigued to try! Thanks!
John Linkon
Badly Looking for this. Thanks.
dwe 2e
Merry Christmas!
Jürgen
If, like me, you are not a fan of cloud services, then you can also use Terraform and Ansible together with KVM libvirtd. I have written a quick start guide for this: https://www.desgehtfei.net/en/quick-start-kvm-libvirt-vms-with-terraform-and-ansible-part-1-2/
I totally like managing my virtual instances via Terraform and Ansible. You can destroy your VMs as often as you want and start them up again in a few seconds. That’s why I summarized my experience with it in my blog.
Nathan Smith
Oh nice! Thanks for sharing!
CRC
It’s a lot of effort and a lot of data loss risk to avoid applying OS updates….
Nathan Smith
Ah right. You can actually deal with the data retention problem (i.e stateful applications) as I mentioned in a comment above, but I really should have spelled out that this article only addresses applications without state.
Sergey
Excuse me, is it not easier to use the cyber?
Or is it like an alternative to it?
Nathan Smith
I’m not sure I know of cyber. Its a challenge to find with a search as you can imagine. Care to share a link to what you mean?
Sergey
Sorry my translation …
https://coreos.com/kubernetes/docs/1.6.1/index.html
Nathan Smith
Ah ok. Yes I would say this approach is an alternative to scheduling your containerized workloads on Kubernetes. Kubernetes has a lot of moving parts so you might want to select this approach if you’d like:
Less complexity
A smaller attack service
Want additional workload isolation (via seperate virtual machines per task type instead of only container isolation)
More consistent runtime behaviour (no scheduling idiosyncrasy. i.e no wierd situations in which the database slows down because it was scheduled on a busy node)
To run workload that don’t fit well in Kubernetes (mailcow comes to mind here)
You might want to use Kubernetes if you’d like:
To write your application specification in a more cloud agnostic way (depending on how you write your Kubernetes resources they can be very portable)
Want to leverage Kubernetes specific applications (Linkerd2)
Want a flexible compute environment because you’re not exactly sure what your workload looks like yet
Want to take advantage of the huge Kubernetes ecosystem (Helm charts etc)
Don’t want to manually schedule everything yourself
Hope that helps clarify the difference 😀
Jason
There is a base level of complexity in running a k8s cluster that your applications may not justify, also some workloads should not be run in k8s even if they can be IMO. They may run fine in k8s but wait till you have to patch or upgrade them
A nice middle ground is to run your stateless apps in k8s and pass off management of the stateful apps ( eg Kafka, relational databases, traditional messaging services, etc ) to the service provider, if available, and/or use Nathans example for those you can’t.
Also there is already a certain level of cloud agnosticism in Nathans example. Containers are portable, you would just need to translate the Terraform to the appropriate provider.